Creating Azure ML Pipelines with Azure Machine Learning Studio V2

If we ask the definition of Artificial Intelligence to 5 different data scientists its not surprising to get 5 different answers. Though the Artificial Intelligence is not new, it was coined back in 1960s and scientists and engineers in big tech companies like IBM are working on some specific use cases for quite a long time. But lately in last decade with emergence of digital technologies such as mobile, cloud an big data its commercial use cases have increased exponentially. Today we are always connected to internet through mobile phones and do a lot of tasks through various apps, such as online shopping, online banking, online trading, social networking etc… and generate huge amount of digital footprint or data. This data generated by people along with digital technologies provides an opportunity for the companies to provide better services to the customers and also help them to increase the customer base.
This is where Big data analytics and Artificial Intelligence comes into picture. As already said there are multiple definition of Artificial Intelligence but to put it simplistically:
Artificial Intelligence is the development of computer systems able to perform tasks that normally require human intelligence. It includes things like visual perception, speech recognition, decision making, language translation etc.
Now AI is a general field of study, but here we are concerned with the subset of AI called machine learning.
Machine Learning is a data science technique that allows computers to use algorithms and existing data to forecast future behaviors, outcomes, and trends on new data. By using machine learning, computers learn without being explicitly programmed.
Azure Machine Learning Landscape
Azure Machine Learning is a family of products which include:
- Azure Machine Learning platform — It is a fully managed cloud service with graphical studio and visual designer. It supports popular python libraries like pyTorch and scikit-learn. It also supports R, the statistical programming language and supports Azure Jupyter Notebooks (it is Microsoft hosted Jupyter notebook).
- Azure ML Studio (Classic) — It is the v1 version on the product and now referred as “(Classic)”. It is low code or no-code interactive visual workspace environment for training and deploying machine learning models. Since this is historical version it has its own issues and pain areas such as there is 10-GB training data limit also the model format are proprietary and non-portable.
- Azure Cognitive Service — These are the set of APIs available as finished SaaS product. It has pre built models for things like emotional and sentimental detection, vision, and speech recognition.
- SQL Server Machine Learning Services/ ML Server — . The SQL Server Machine Learning Services provides statistical analysis and predictive analytics, supporting both Python and R programming environments for SQL Server databases. So we can essentially build and deploy ML models inside SQL Server. The Microsoft Machine Learning Server is a standalone enterprise server for predictive analysis. We can build and deploy models using pre‑processed data. It’s cross platform, runs on Windows Server and Linux.
The idea here is that Microsoft learned a lot from their v1 ML Studio product. They realized they wanted to give data science teams and AI engineers a unified workspace where each team member can do his or her own work. We are going to find that this new Azure Machine Learning Studio supports things like Azure role‑based access control such that you can have folks who are maybe not data scientists, but more Azure infrastructure professionals being able to take control of the underlying compute infrastructure, and then data scientists and AI engineers, depending upon what their background is, they can collaborate and the tool will meet them where they are.
In this discussion we are going to deal strictly with the current edition of latest version of Machine Learning Studio.
Before moving ahead I would like to mention that this article is not about ML algorithms or models. This article is about how can we use Azure Machine Learning Studio graphical interface to build ML pipeline without using any code.
Getting Started with Azure Machine Learning Service
To build ML pipeline first login into Azure portal i.e. portal.azure.com. Open All services and look for “AI+ machine learning”. It will provide multiple options, we click on “Machine learning”.
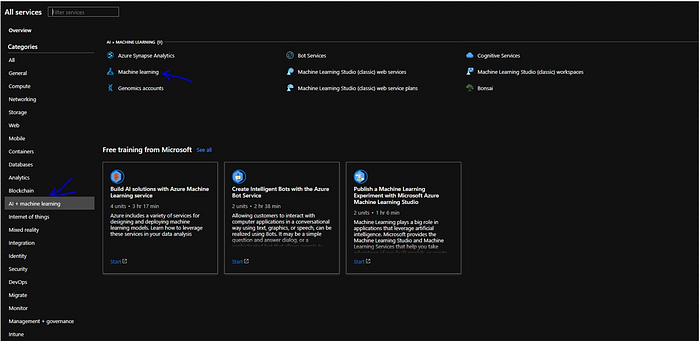
As we can see there are multiple services, now there is Machine learning service what we refer to as V2 and then there are service referred as classic which is the older version of Studio. Now this take us to a blade and ask us to create “machine learning workspace”.
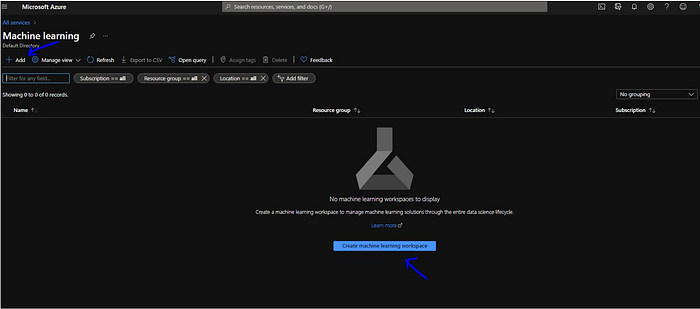
Before moving ahead lets first understand what is ML workspace.
Azure Machine Learning Workspace (AML Workspace)
Azure ML Workspace is considered the top level resource in Azure Machine Learning family. It provides the centralized place to work with the Azure Machine Learning Service. So its like a logical container which holds all the resources and associated with Azure Machine Learning Service. Azure provide us different ways to create AML workspace, we can create it through Azure portal, ARM template for programmatic deployment, Azure CLI, VS Code with AML extension or we can create it by using AML SDK for Python or R. For this article we will use Azure Portal to create resources.
So when we Create new Azure Machine Learning Workspace we need to provide Resource Group, Workspace Name and Region. When new AML workspace is created, it automatically creates a storage account, key vault, application insights and container registry.
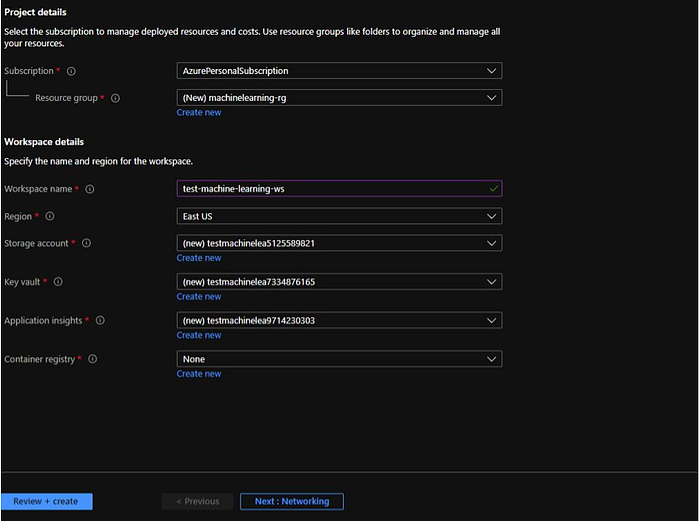
Now click on Next to add the Networking details. We can restrict the connectivity method here to public or attach a private endpoint to restrict its connectivity from specific network. We will keep default as public endpoint.
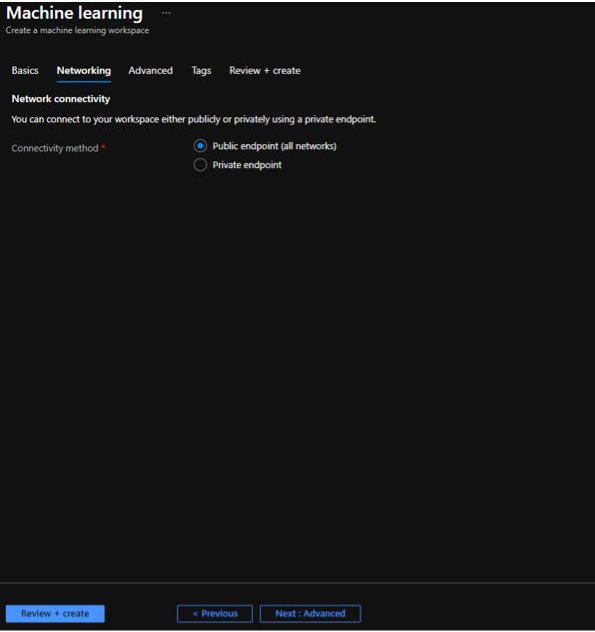
Next we will provide data encryption type. Here we can configure whether we want to use Microsoft-managed keys for encryption or if we are using some custom keys across enterprise then we can provide those details here. We will keep Microsoft-managed keys.
Next we will add tags and move to Review + create tab. Here azure will validate the details provided and if validation is passed it will allow us to create the workspace by click “Create”.

Once we hit create a new but empty Azure Machine Learning Workspace will be created. As already mentioned it is a container to hold all Azure Machine Learning service resources and we perform all the action in Azure Machine Learning Studio. So we click on “Launch Studio” button to open the studio. Also, there is a link to download config.json associated with this workspace. This is used by the developers to register the projects and source code into the workspace.
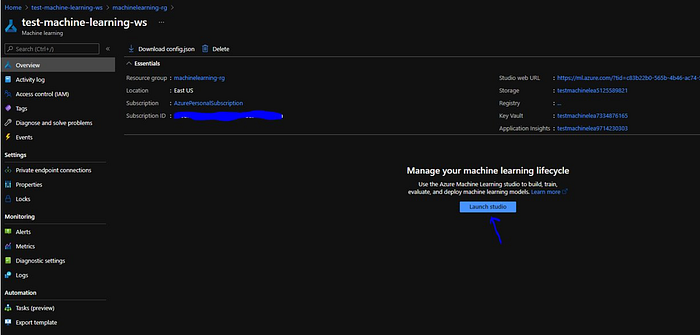
Azure Machine Learning Studio
When we click on Launch studio, It will open in a separate tab and this bring us to ml.azure.com.

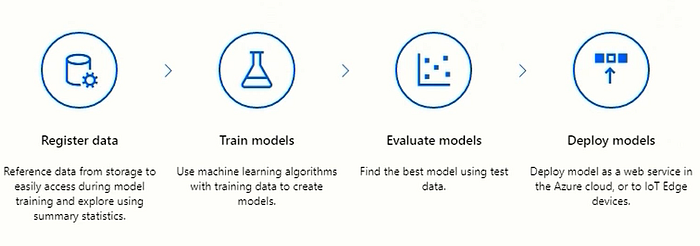
When we login to ml.azure.com we will get general pattern for machine learning. It says first register datasets in the workspace, next bulk of the work will be training models using various machine learning algorithms to generate accurate predictions. Next we will evaluate the model against the test data an finally deploy models as webservice using different compute targets.
Azure ML Studio is divided into 3 sections i.e. Author, Assets and Manage. Author — section give us provision to use code-first approach using Jupyter notebook. If we are not sure which machine learning algorithm us best for us we can do Automated ML run where Azure, taking advantage of massive parallel compute, can try out a whole bunch of different algorithms, and we can pick which one is most accurate. Also if we are not comfortable with the code it provides us provision to use graphical designer.
Assets — Here the idea is of collaborative shared workspace. We can register datasets, experiments, create pipelines, models and endpoints that we can share. All the changes we do are being tracked version wise. We will be go in details while creating pipelines.
Manage — This section contains is to manage the infrastructure that’s underneath Azure machine learning, that’s where we have Compute, Datastores, and Data labeling. We will in further details while deploying pipeline.
Build Azure Machine Learning Pipeline
Now we understand the basics of Azure ML workspace and Azure ML Studio lets create first ML pipeline using Designer. so click the designer icon in left nav of Studio, it will show you following screen which contains whole bunch of samples. We will also use one of the pre-built module i.e. Automobile Price Prediction for this discussion.
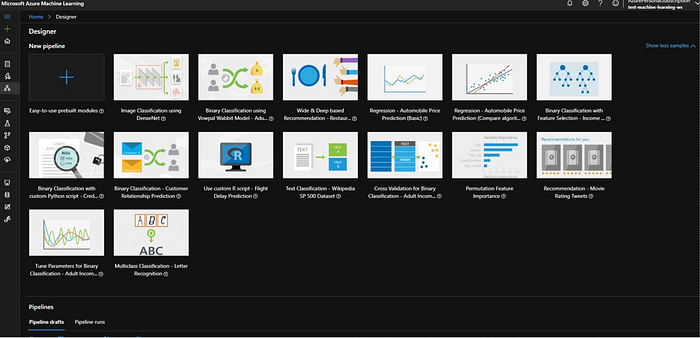
Under new pipeline click on “easy-to-use prebuilt modules” which will create a brand new pipeline. It will open a new screen which has Autosave feature which is nice. I recommend you to keep it on.

Now as we can see in Settings compute target is selected so lets select a compute target by clicking Select compute target link:
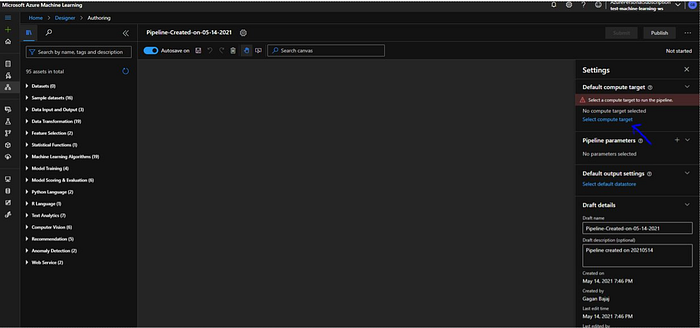
Now it will provide us 2 options either we select existing compute or create a new one.
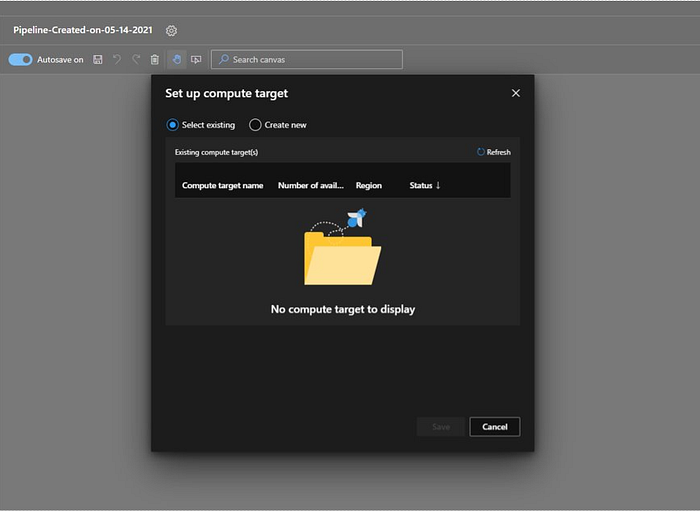
Since we don’t any existing compute we can go ahead and select “Create new”. Azure will recommend us a predefined configuration, if we want control over how that cluster looks, in terms of its allocation of CPU, RAM, storage, and node count, we can go to Compute and then Training clusters. Here we are fine with predefined configuration so we provide name to the training cluster and click “Save”.
After saving new training cluster, we have to wait for some time as Azure will provision required resources. We can check the status in Setup compute target.

Once the training cluster is available we will be able to select it as compute target. After select the compute target we can update the name of the pipeline to “Test Auto Price Prediction”.

As discussed first step we need to do is to bring in the data. So next we will expand Datasets category and a bunch of modules here for sample data. To get the custom data we can store it in datastores and then they will be available here as datasets, but we are using the sample dataset for this article so we will select Automobile price data from the sample datasets and drag on to designer.
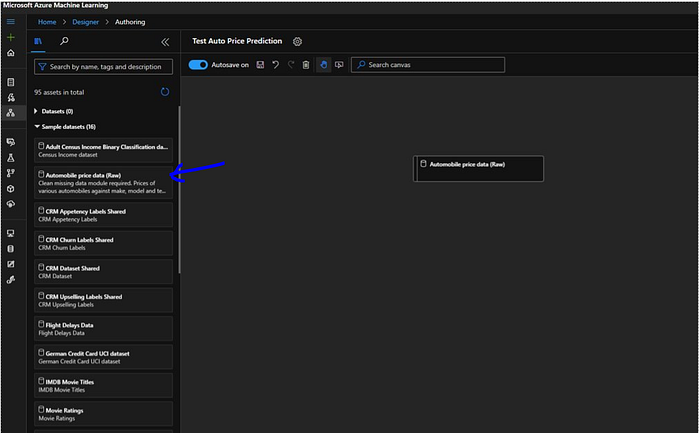
Now we will open the settings tab for the Automobile Price Data, it automatically open when we drag it and if we need to open it again we can select the task and setting tab will reopen. We will go to output tab and click the visualize button.

This shows us what data in this dataset looks like. It tells us that we have 26 columns and 205 rows.
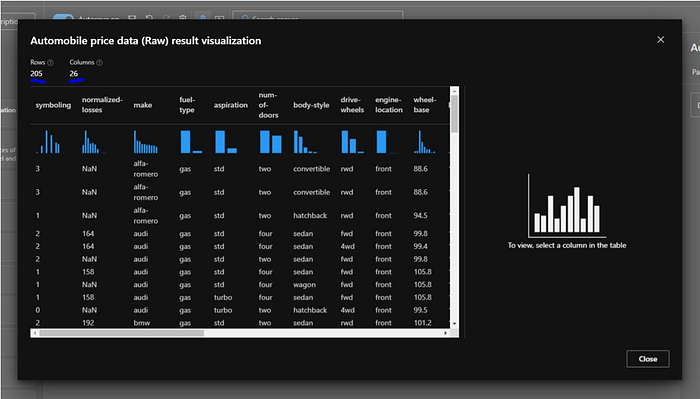
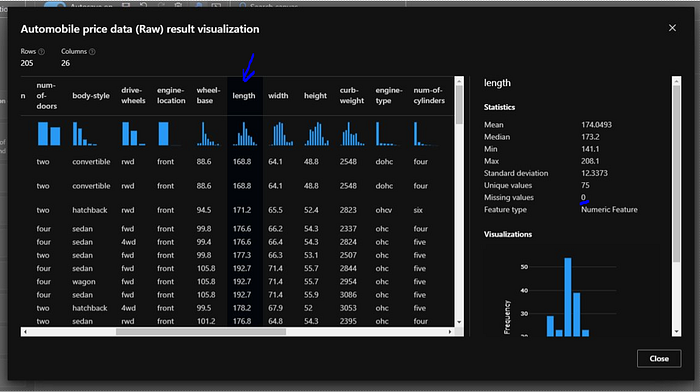
We can scroll through and we can see the different types of data that we’re analyzing in this price data dataset. Based on these various properties, and when we select one of these categories, we can see some statistical data over on the right, including, importantly, the unique values and the missing values. We want to keep an eye out for columns that contain missing data because that can affect our model accuracy.
To clean the data we need to perform action on existing columns. For that we will select “Select Columns in Dataset” from Data Transformation section. Also notice that these modules has one or more ports. Here Automobile price data has output port and Select Columns in Dataset has input port, we can drag and drop a connector between two.
Next we will select “Select Columns in Dataset” to open the settings and click “Edit Column” to include the specific column names.
Now have looked into the dataset and identified that there is a column called “normalized-losses” which has lots of missing values so we will exclude that column.
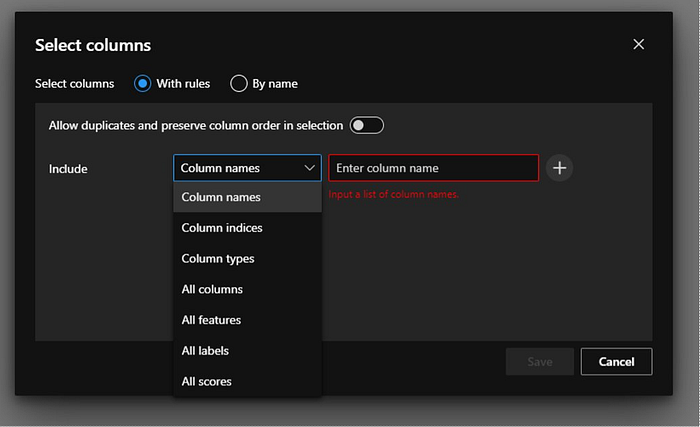
To do so we will first include all the columns.
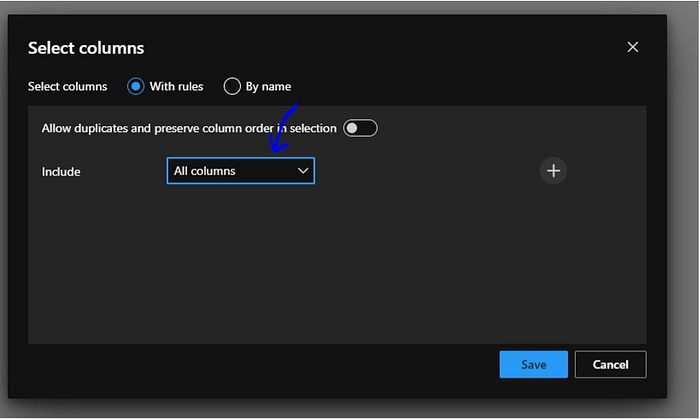
Then will add a row and and exclude the column name.

When we select “Exclude” it will give us the pop up which contains all the columns names and we will select “normalized-losses” column
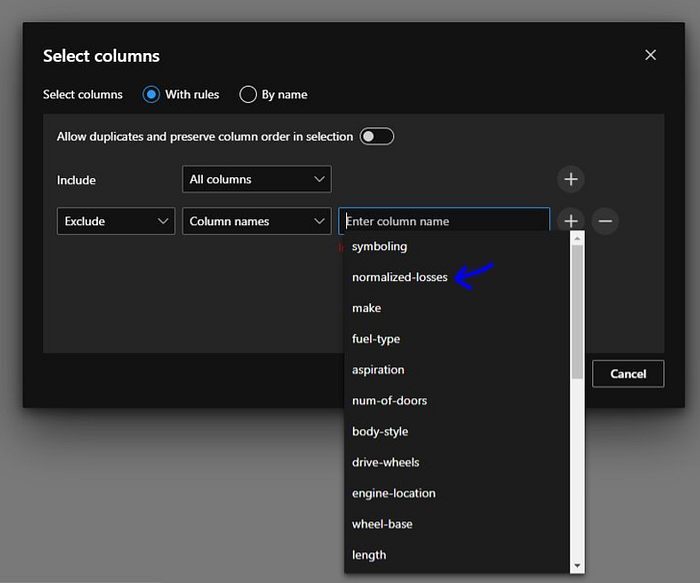
Now we hit “Save” to save our changes.
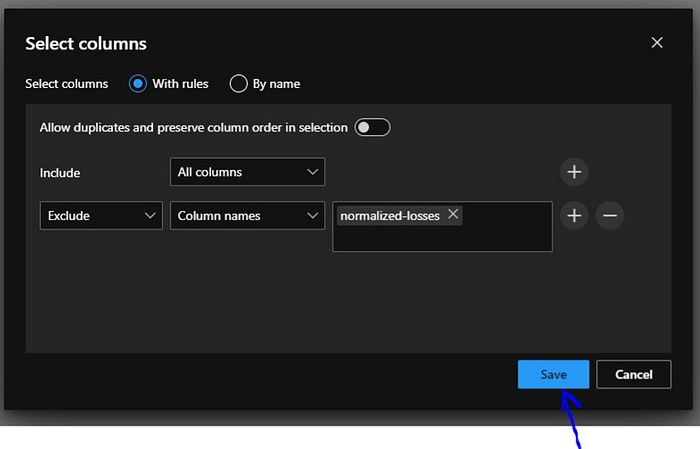
Now our columns are selected, as we can notice for all these elements which we add to our pipeline we can change compute target. This is useful when we have step which is resource intensive and we want to run it on separate cluster.

Now we will remove the missing data by removing missing value rows. We will go back to module list and within that to “Clean Missing Data”. Then we will drag and drop a connector “Select Column in Dataset” module.

For cleaning rows we will go to the configuration and under “Cleaning Mode” we will select “Remove entire row”. So anytime there’s a missing data it will remove the entire row. Also we need to select the columns to e cleaned so we will hit “Edit Column”.
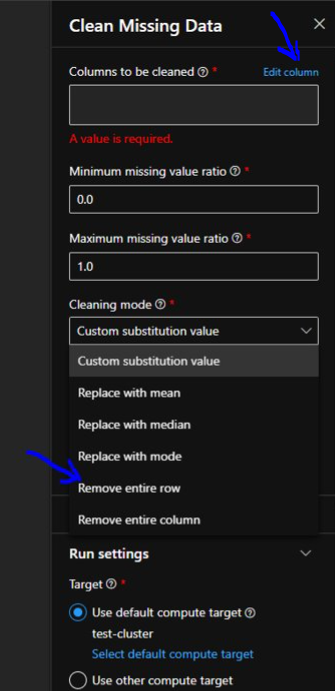
We will get a pop up window to select the column to be included in cleanup activity.
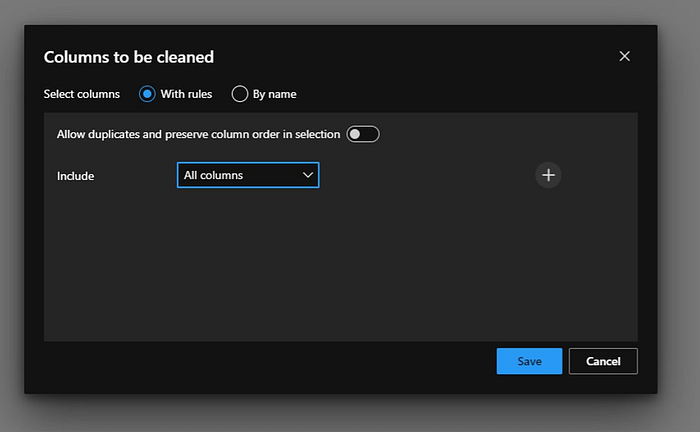
As we have done before we will add “Exclude” rule and select “normalized-losses”. Now will hit on “Save” to save the changes.
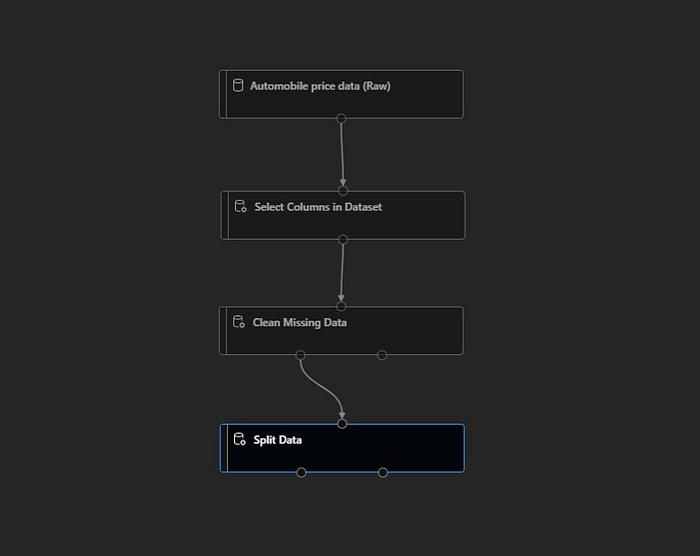
Next for training we will split the data into 2 datasets i.e. one for training and one for testing. And to do that we will drag and drop “Split Data” module.
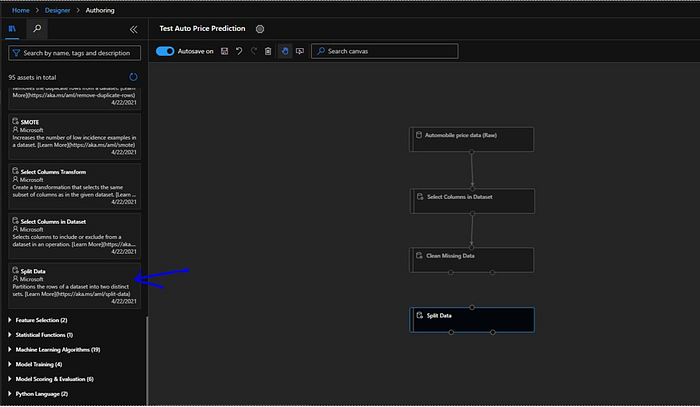
As we can notice “Clean Missing Data” module has 2 output ports, so we will connect “Split Data” module with left port of “Clean Missing Data”. Also in configuration “Fraction of rows in the first output dataset” we will split the dataset into 70:30 ratio by adding value as “0.7”.
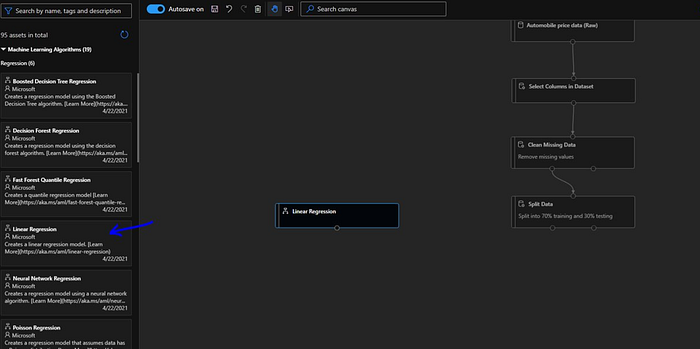
Next we will train the model, and we will select “Linear Regression” module here which is available under “Machine Learning Algorithms”.
We will also bring in “Train Model” module which is available under “Model Training”.
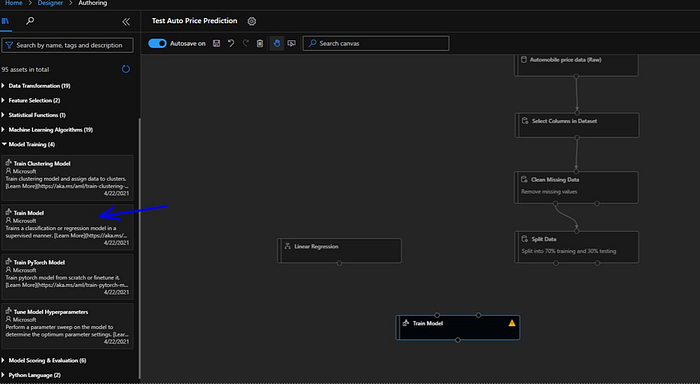
Next we will link “Linear Regression” with left input port of “Train Model” module. Also will connect left port of “Split Data” module left output port with right input port of “Train Model”.
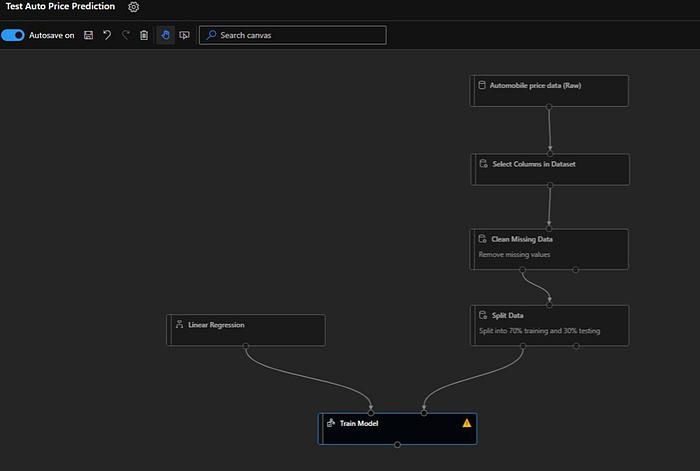
As we can see there is an error icon on “Train Model” module. Next we need to tell which columns to predict (which is the reason for the error). So in order to that we will open the configuration section of “Train Model” module and then “Edit Column”.
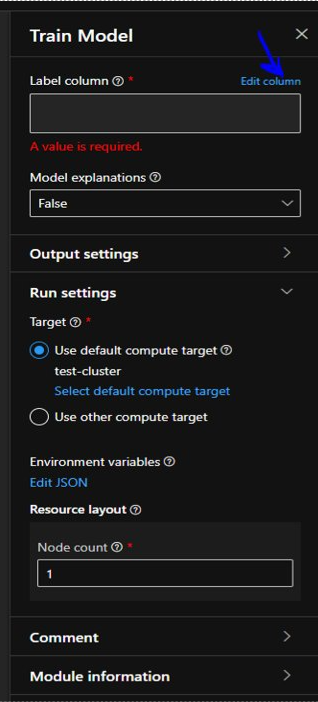
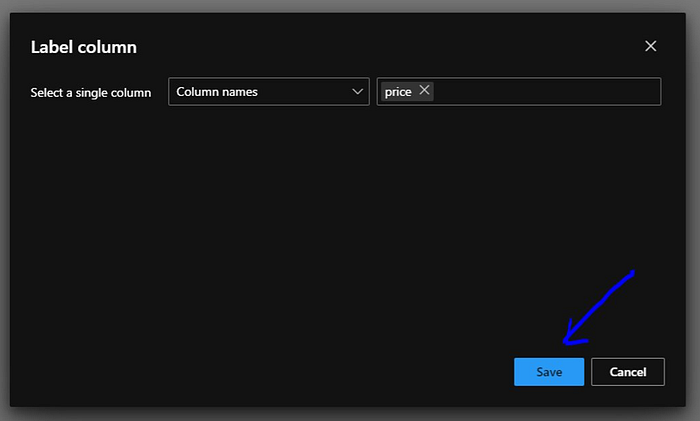
“Label Column” popup will appear and here we will select the name as “price” which it will predict and the hit on “Save”
Now as we can see the error is gone, next we will going to evaluate the model.
In order to that we will drag and drop “Score Model” module which is under “Model Scoring and Evaluation” on the canvas. We will connect the output port of “Train Model” module with left input port of “Score Model”.
Next we will bring in “Evaluate Model” and connect the output port of “Score Model” with left input port of “Evaluate Model”.
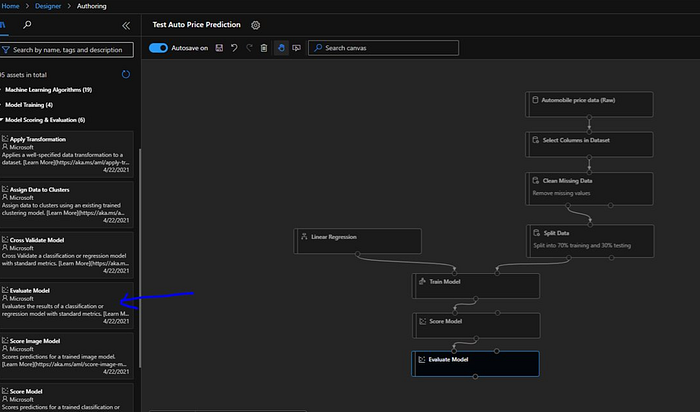
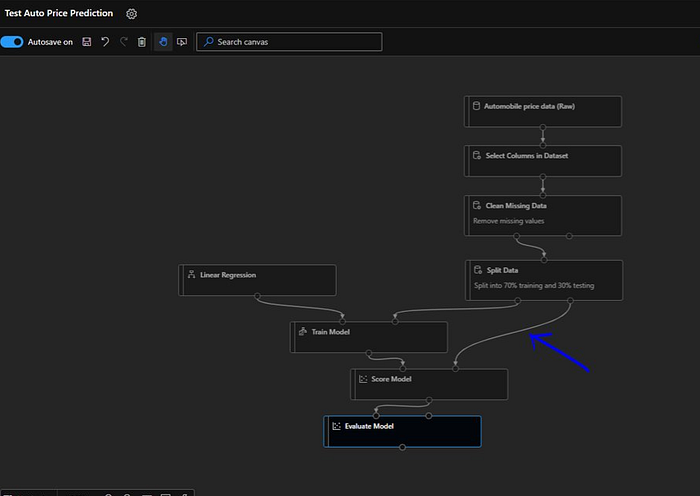
Now we can’t forget about our split here, we are putting 70% of the data through our training process but we need to put 30% of data through test process as well. So, in order to do that we will connect right output port of “Split Data” module to right input port of “Score Model” module.
Deploying Azure ML Pipeline on Test Cluster
Now our model is complete and we are ready to run this. Let’s go and do that by hitting “Submit” button.
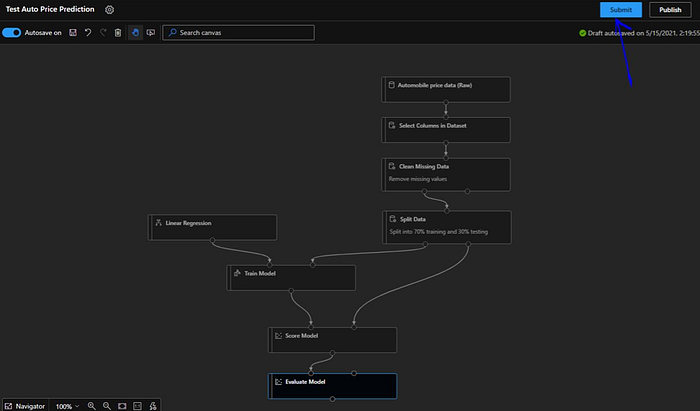
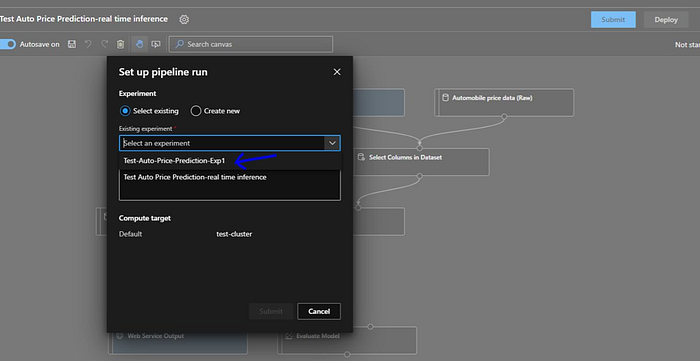
Now a popup will be displayed to select the “Experiment” or to create a new one. Now the experiment is essentially a container that’s going similar pipelines runs together. Also, we need to select the compute target, if we have not created then we have to create one first before we can submit the experiment. Fortunately we have already create a “test-cluster”.
Since we don’t have one, we will create a new one.
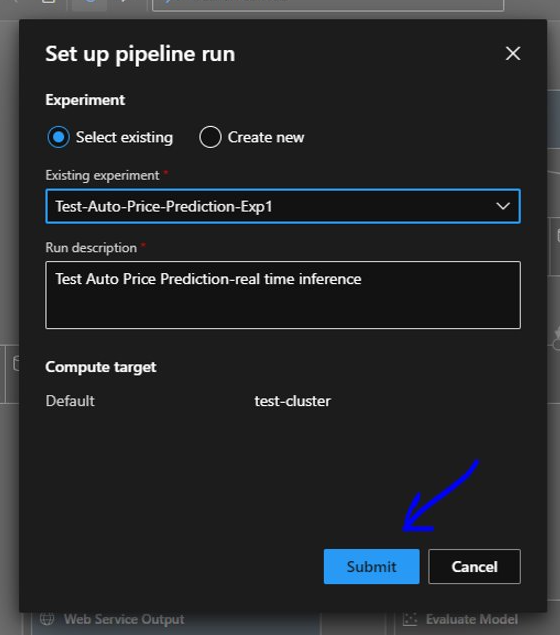
We will name it as “Test-Auto-Price-Prediction-Exp1” and then submit it.
Now we wait, we can see its in running state. This will take few minutes complete.
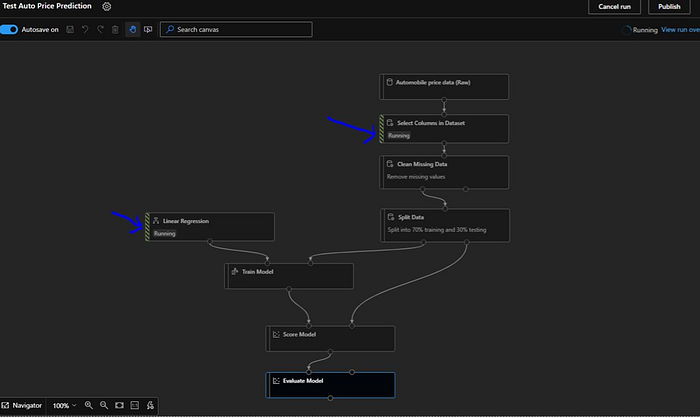
We can see a pattern around the modules which are currently executed.
In the mean time we can go and check the compute tab. Here we can see that 2 nodes are up and running.
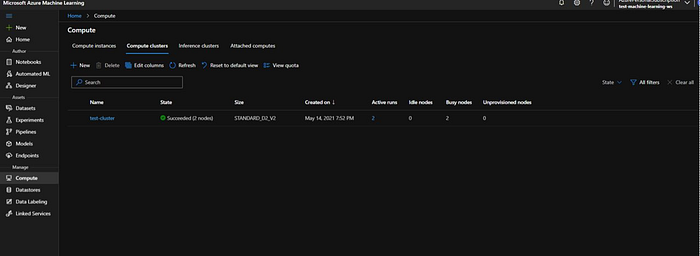
We can see there details by clicking on “test-cluster”
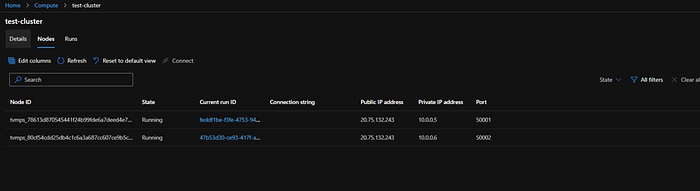
All-right so now we can see all the modules are executed successfully.
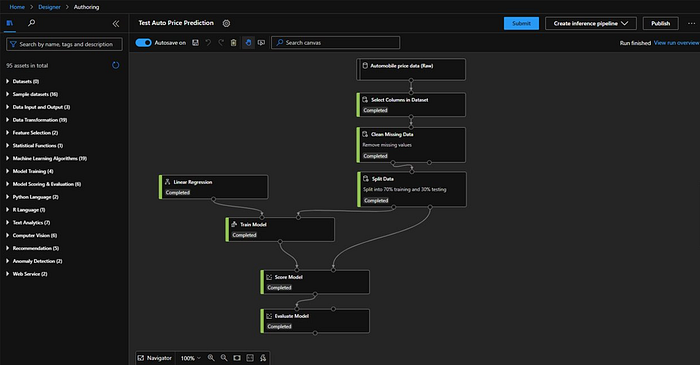
Now we will inspect the score model first. We will go to “Outputs + logs” and click on “Visualize” icon.
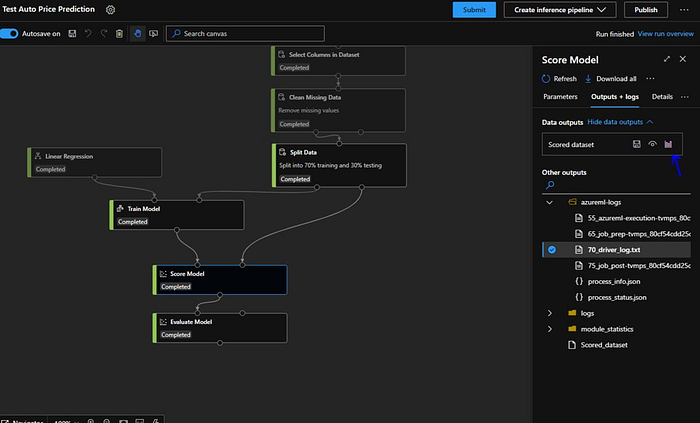
“Score Model” visualize pop up will open and then we will look for “price” field in it. Remember its the same column we selected for prediction while configuring “Train Model” module. “price” column contains the original automobile prices also we see the scored price next to it. Our goal here is to see how closely our linear regression machine learning model is predicting those prices.
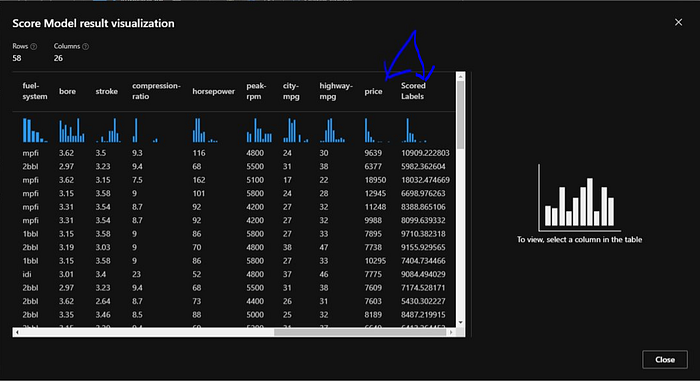
Next we will look at the evaluation data, for that we will “Evaluate Model” configuration and again click on “visualize” icon.
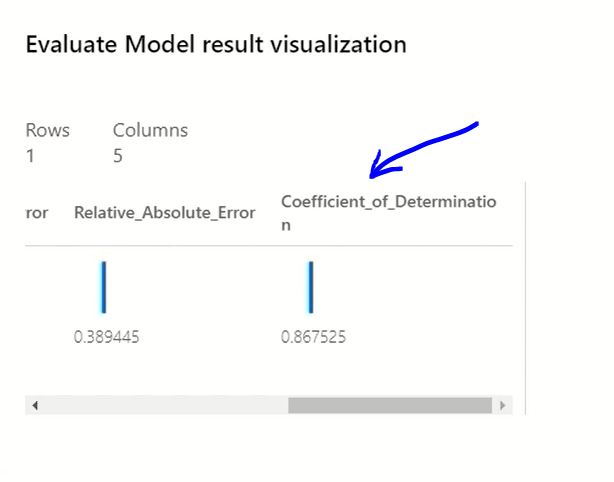
There are various error statistics available. Smaller the value of these error statistics better they are. Here we will look for “Coefficient_of_Determination”, it is suppose to be close to 1. As we can observe below it is a very good model.
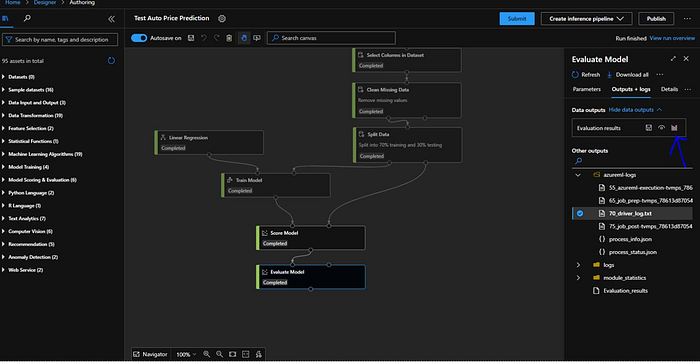
Inference Pipeline
Next we will create the inference pipeline. When we click on the drop down “Create inference pipeline” next to “Submit” button, we will be presented with 2 options “Real-time inference pipeline” and “Batch inference pipeline”. We will select the “Real-time inference pipeline”.
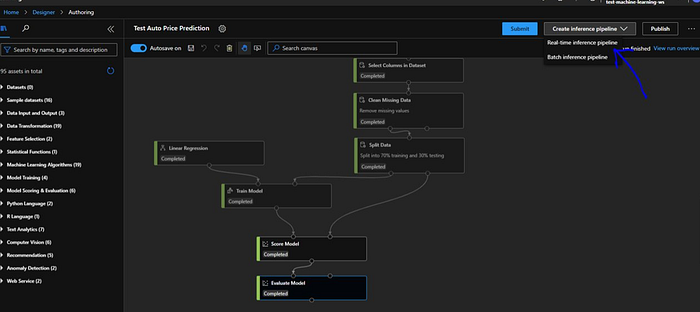
When we create a inference pipeline which will be generalized, the training modules are gone away and we can notice that Azure has added a “Web Service Input” and a “Web Service Output” module.
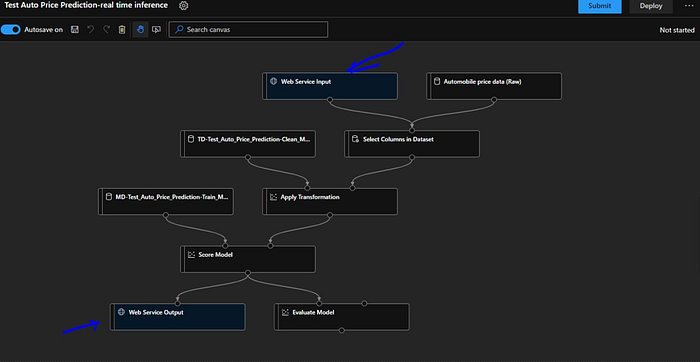
Most of the work is already done for us, so we need to “Submit” it so as to make sure model is still working fine. We can reuse out experiment that we created and run previously.
We will use our same training cluster i.e. “test-cluster” for this and click “Submit”
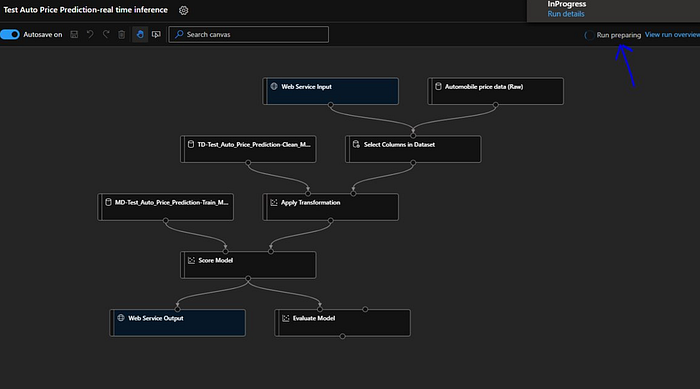
As we can see its in running state. So we have an opportunity to create “Inference Cluster”.
We will go to the “Compute” tab and open “Inference Clusters”. Currently there are no clusters are available. We will create a live AKS cluster that we will run for the endpoint itself. So we will click on “New”.
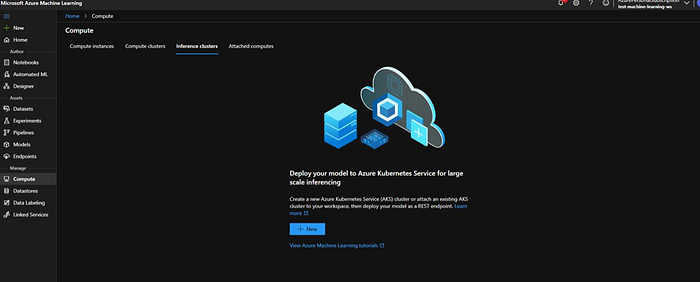
Under “Kubernetes Services” we will select “Create New” radio button and select location as “East US”.

Now it will give us option to select the VM family as compute. We will select “Standard_D2_v2". We can select any other VM based on our compute requirements.
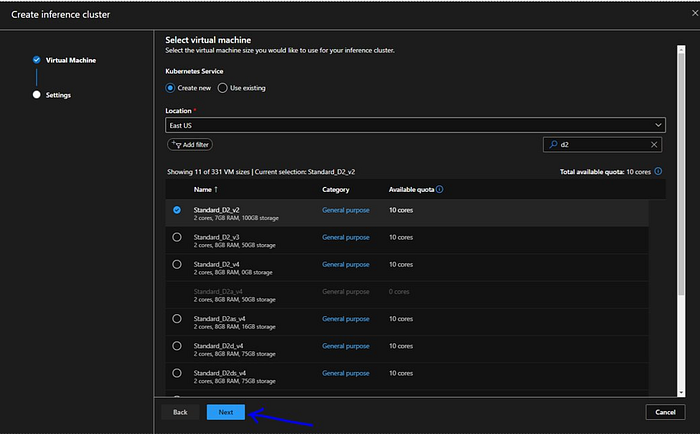
Next we have to provide other configurations such as Compute name, Cluster purpose, network and SSL configuration. We will select “Dev-Test” as cluster purpose with 2 nodes, “Basic” as network configuration and for this demo will keep SSL configuration as disabled. Now we will hit on “Create”.

As we can see its in Creating state, it will take around 15–20 min to create.
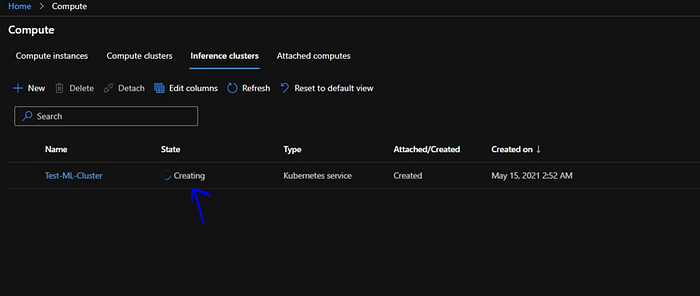
Once the cluster is ready the state will change to “Succeeded”.
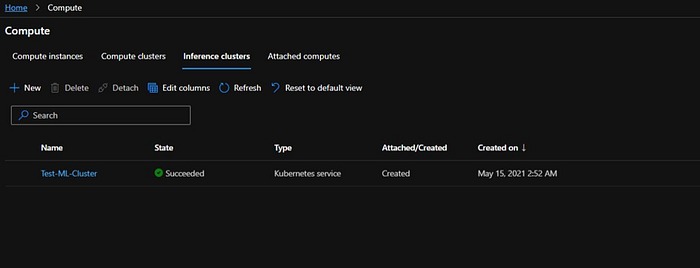
Now we will go back to our “Real time inference pipeline” which has run successfully. And we will click on “Deploy”.
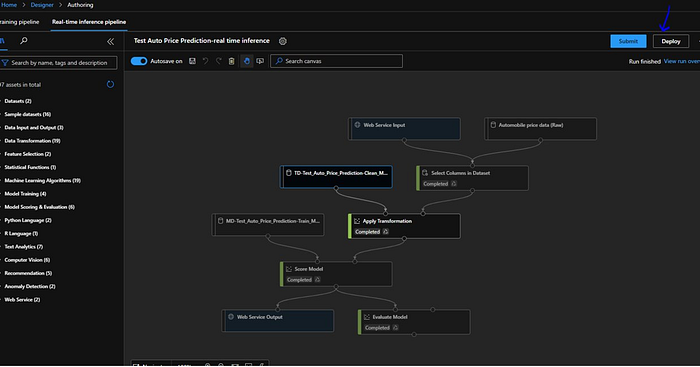
It will ask for either we can “Deploy a new real-time endpoint” or we can replace an existing one. We will keep the name as “testdeployment” and select the compute type as “Azure Kubernetes Service”. Next we will select our compute name from the dropdown which we just created “Test-ML-Cluster”. and then hit “Deploy”.
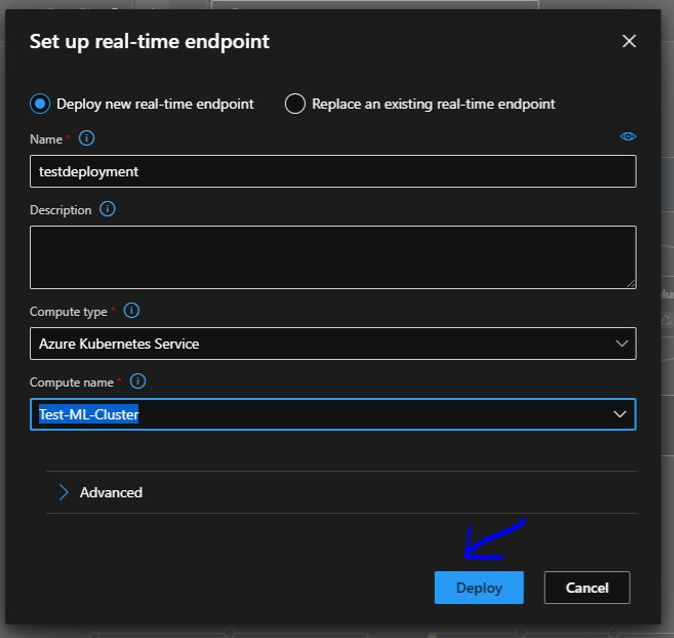
As we can see in the banner up there it is creating the endpoint.
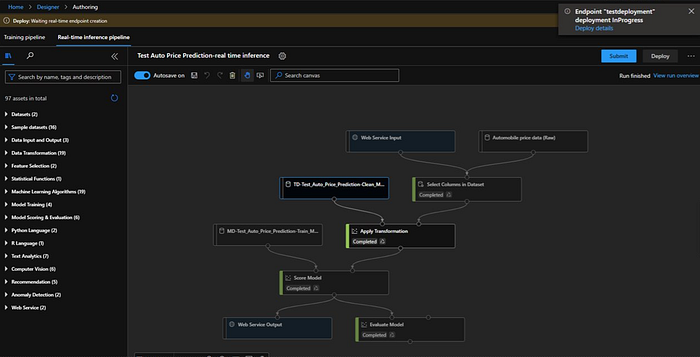
Now the deployment is succeeded, we will click on the link “view real-time endpoint”.
It will open up in separate tab. On the details page we can see the actual URL of the endpoint. Also it will provide the information whether we are using key or token-based authentication.
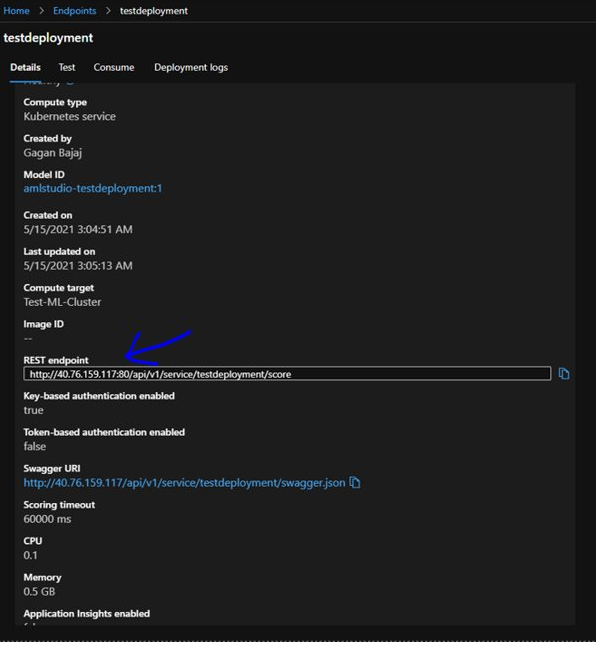
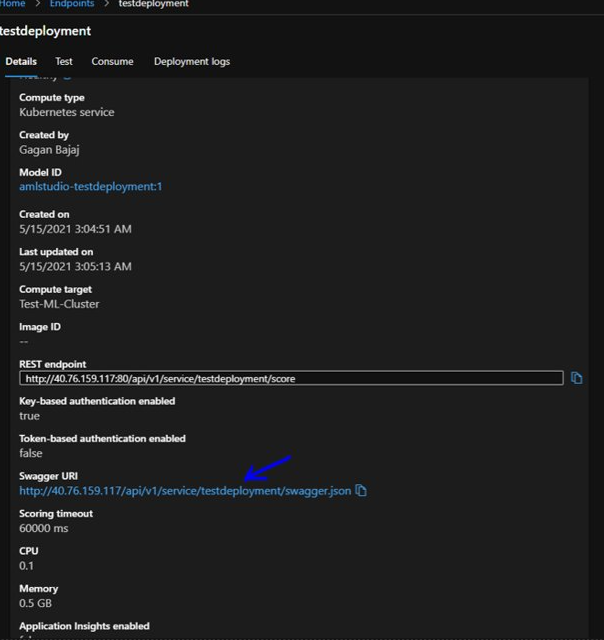
It also provide us URL for swagger documentation and direct link to draft pipeline.
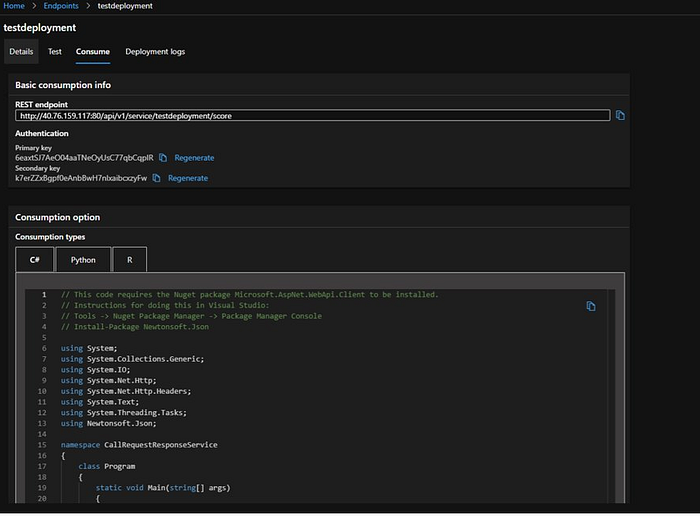
On consume tab we can find the information which we will share with our developers and data scientists. We can also configure the authentication using key or token-based. Then we hve consumption source code in C#, python and R.
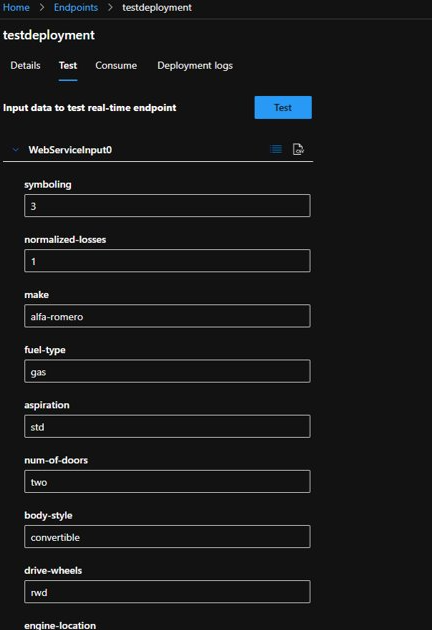
Under the “Test” tab Azure and put in some sample data from original training set. The purpose is we can provide live data here, click “Test” and run through that pipeline and get the results.
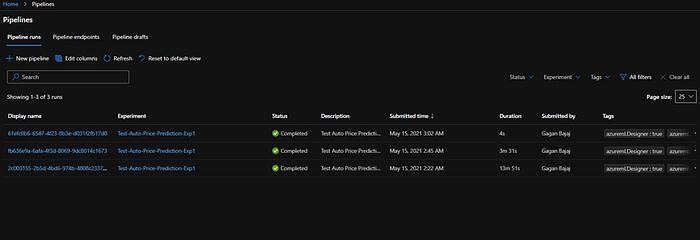
If we come back to our “Pipelines” and see there are 3 runs of our pipeline
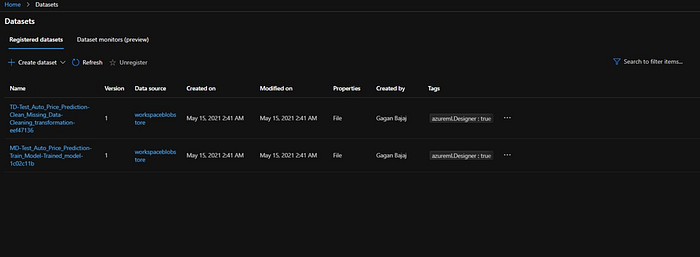
If we go to the Datasets tab we can see our training and test datasets.
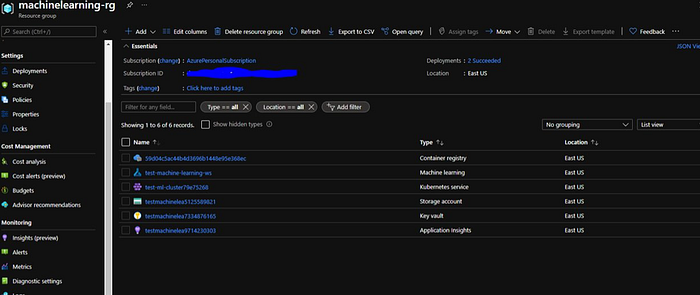
If we look into or original resource group. These are the resources which will be created.
Next important step is to cleanup the resources so we are not charged for the resources we consumed…
